Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
In this Discussion
What makes an image AI-generated? Patent diagrams for a computational Bokeh effect (code critique)

Recently, discussions surrounding AI image generation and computational creativity have come into the mainstream, often accompanied by claims of theft and exploitation (Jiang et al. 2023). These debates tend to assume a clear category boundary between images generated by AI and those created by humans. While such a boundary arguably exists in the realm of digital art, that boundary is fuzzier in the realm of photography.
In this code critique, I'd like to look at the boundary between human and computational authorship through some of the technologies used by smartphones to produce photographic images. While the technologies at work have avoided questions about authorship and copyright (authorship is attributed to the human behind the camera), many of the same issues regarding theft, competition and hegemony may be arising more quietly.
Ideally, this sort of inquiry would turn to the source code for smartphone image processing applications. Unfortunately, the methods used by these programs are important to competition between smartphone manufacturers; camera photo quality is an essential selling point, and the methods used to take "better" photos are kept under tight wraps. The only information we have regarding these algorithms comes from patent applications. So this code critique will look specifically at five technical drawings from a patent. Specifically, US Patent 11,094,041B2, "Generation of Bokeh Images Using Adaptive Focus Range and Layered Scattering" issued in August 2021 to George Q. Chen, an engineer at Samsung. These drawings illustrate a technical method for a "bokeh" or background blur effect which might be used now or in the near future in Samsung smartphones. I am a computer vision researcher and not a lawyer or patent expert, I will interpret these diagrams as a representation of a computer program which we can critique in much the same way as source code.
Figure 1
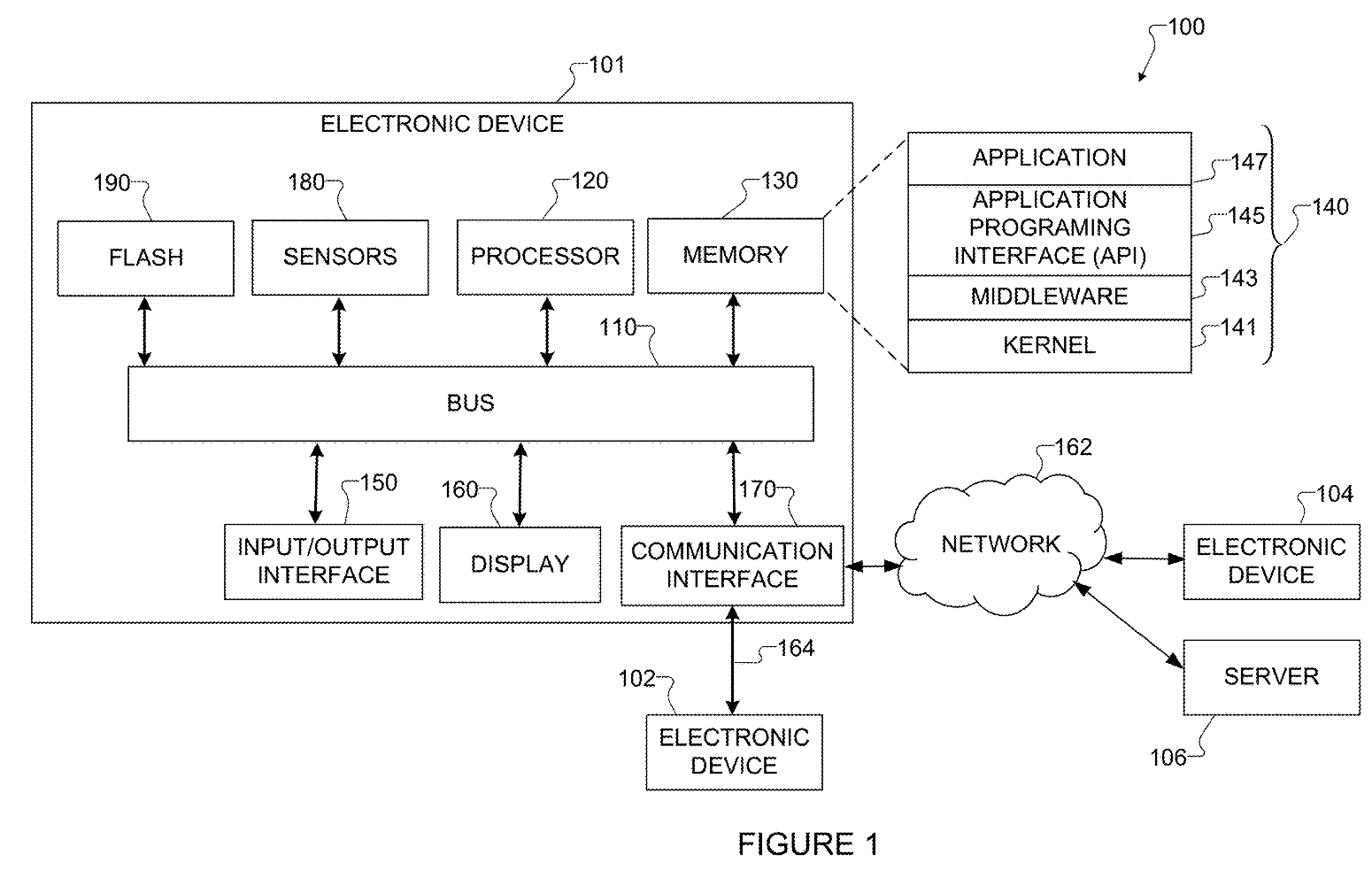
"Figure 1 illustrates an example network configuration including an electronic device in accordance with this disclosure." In other words, a diagram of a smartphone system the technology could be deployed on.
Colloquially, we talk about smartphone "cameras" as camera devices, similar to the digital cameras of the 20th century. From the user's perspective, these cameras are very similar. They use an image sensor to capture light on command, and then apply image processing to recover a human-viewable image, which is digitally stored. However, smartphones are internet-connected computers, with processors faster than the desktop computers of a few decades ago. That means the image processing step can be highly complex, including anything from traditional signal processing to deep neural networks, and some steps may even be completed off-device, if the user has consented. These steps are part of the photographic process in between the press of the shutter button and the appearance of an image, not a later editing step.
Figures 2 and 3
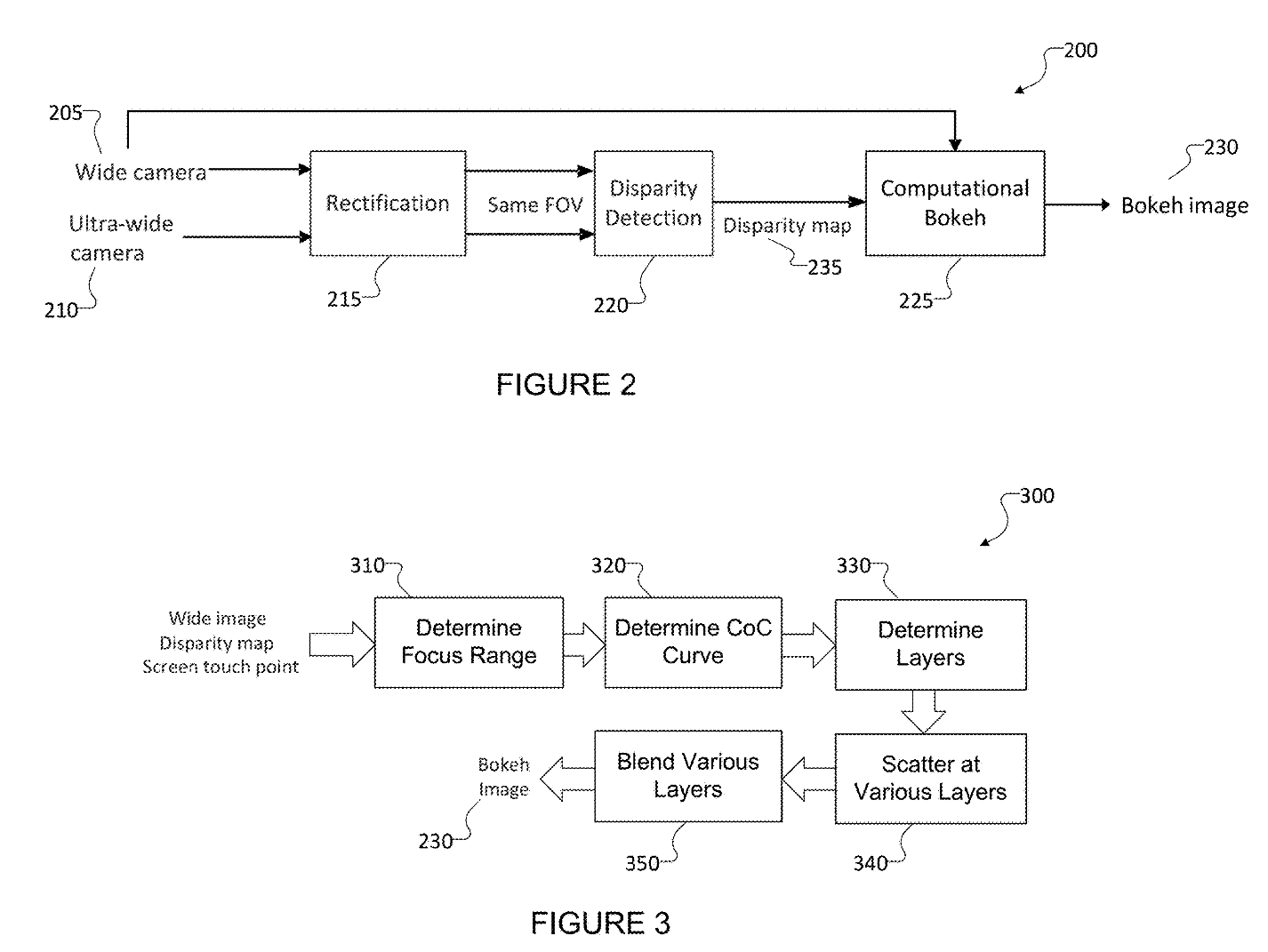
"Figure 2 illustrates an example process for creating a Bokeh image using an electronic device in accordance with this disclosure. Figure 3 illustrates an example process for applying computational Bokeh to an image in accordance with this disclosure." In other words, Figure 2 shows the whole process and Figure 3 shows the computational step.
The word "Bokeh" comes from the Japanese verb 暈ける (literally "to blur") and refers to the aesthetic quality of images which are blurred beyond the focal length. Its usage in computational image processing comes from its usage in photographic method books (such as Kopelow 1998). Skilled photographers can achieve this effect using film-based cameras by varying the focal length (distance between film and lens) and aperture diameter (size of the opening behind the lens). Smartphone cameras do not have these moving parts and thus cannot achieve the same effect optically, so they simulate it using image processing.


Two photos of a bookshelf, one with a computational bokeh effect applied to blur the (hopefully familiar) book in the background.
The aesthetic appeal of blur in images highlights a tension between art and engineering. Classically, cameras and image processing algorithms were evaluated based on visual accuracy — how perfectly they captured and reproduced a visual signal. But humans take photos for a variety of reasons and often have aesthetic goals which prioritize visual indeterminacy and abstraction over accuracy.
But ironically, simulating the blurry indeterminacy of Bokeh requires more information about the three dimensional scene than the original two dimensional image. Specifically, it requires information about the depth of each pixel to distinguish the foreground from the layers of background. This information can be recovered from two images taken by cameras at the same time from slightly different perspectives, like the "wide" and "ultra-wide" camera described here, by playing a "spot the difference" game and measuring the disparities between the two images. Because of the parallax effect (think of how fast the trees move relative to the mountains when you look out a car window), the disparity map contains that depth information.
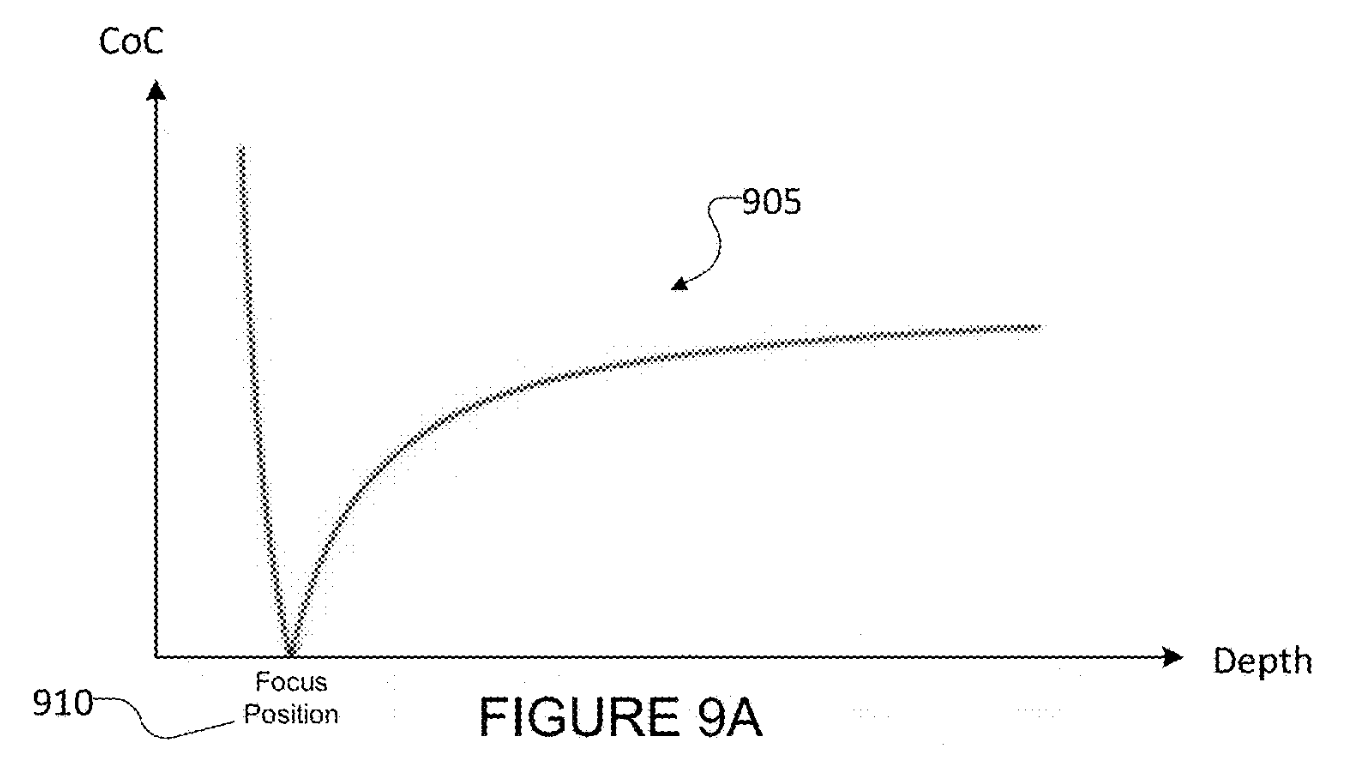
After finding the disparity map, this algorithm computes a circle of confusion curve, like this one above, which relates the depth of each pixel to the radius of the circle it will produce when out of focus. You can see this in your own vision if you hold your finger close to your face and focus on it with one eye closed. Small points in the background grow larger, the closer your finger is to your face, and the further an object is away from you, the larger its circle of confusion will be. By blurring with the right radius at each layer of the image, the algorithm produces a computational Bokeh effect which is indistinguishable from the optical version.
This bokeh effect was historically part of the specialized knowledge of a professional photographer. Understanding of the photographic process and familiarity with a camera allowed photographers to expressively produce these effects in images. Now, amateur photographers can produce the same effect by making use of the specialized knowledge that has been built into the camera software itself. These effects deskill photography, allowing amateurs to produce "professional-looking" photos.
Figures 4 and 5
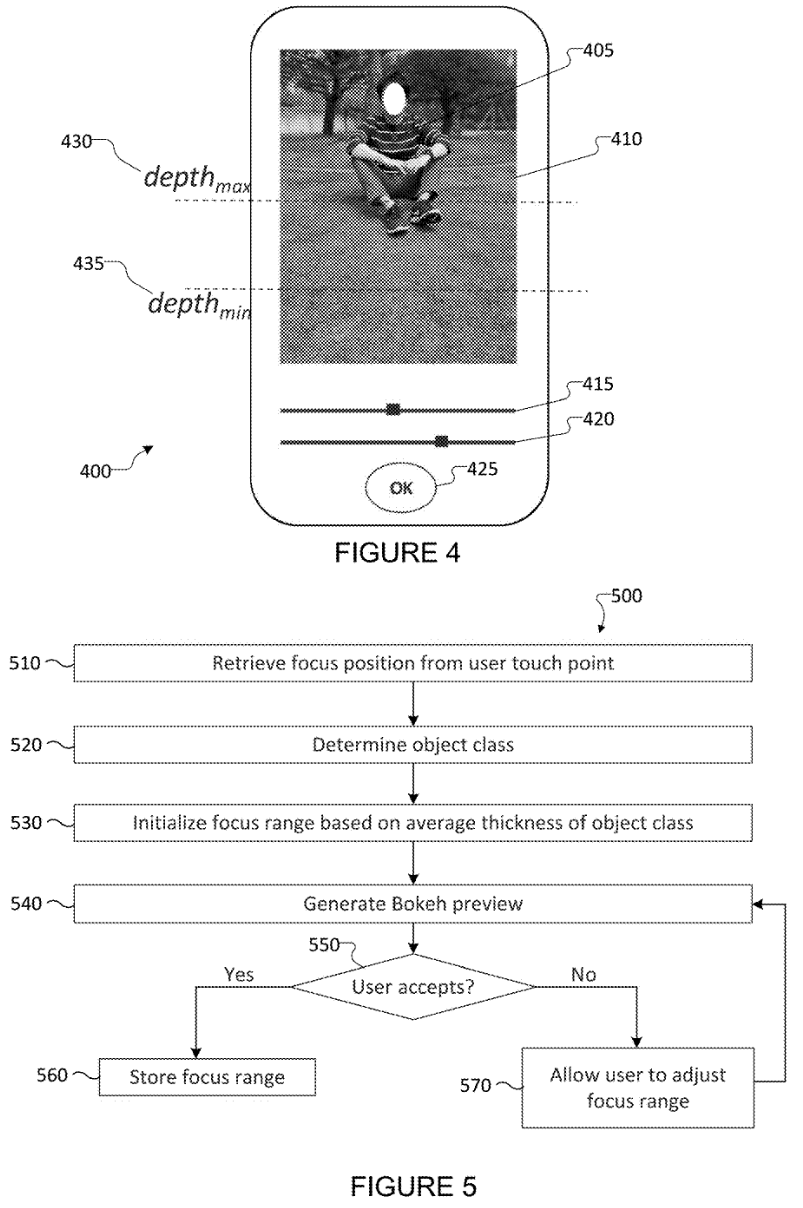
"Figure 4 illustrates an example user interface for receiving touch inputs that define a depth of focus range in accordance with this disclosure. Figure 5 illustrates an example method of determining an adaptive focus range in accordance with this disclosure." In other words, Figure 4 is a drawing of an interface where the user can tap to specify the depth they want and Figure 5 shows the algorithm behind it.
Rather than specifying the depth of field using the physical aperture and focal length, smartphone users can specify this parameter using a more intuitive tap on the object of focus. Again, though, an easier user experience requires more information from another source. In this case, the source is an object recognition algorithm, which identifies the class of object the user tapped on. This step is essential to know the range of depths that the user is interested in. From the patent, "a person object class may define the average thickness of a human to be about 0.55 meters. Various object classes can be defined based on a number of different objects, such as people, cars, trees, animals, food, and other objects." These objects are classified using deep neural networks, likely trained on millions of photographs taken by human photographers. While Samsung's specific dataset is not described in the patent, it likely resembles the COCO dataset which is often used for training object detection models.
Even though the user can manipulate the sliders to manipulate the inferred depth of field, the inference step imposes normative assumptions upon the photograph. When you capture a person, the depth of field should be large enough to capture their entire body, not just part. Your object of interest should be from a small family of common object classes with known thickness values. This system draws on the visual language of millions of previous photographers to determine how to process a new image. Even though the new photo does not come out of a deep neural network, its manipulation has been shaped by the contents of a large dataset.
Going through this algorithm, we see several parallels to the debates over AI art. Advances in hardware and software technology create a new way to generate digital images from signal data by making use of past works. Innovations in user interfaces make these image generating technologies easy to use by amateurs, directly competing with the professionals whose work was used as training data. But the simplicity of these interfaces requires imposing normative assumptions about what the user is trying to do, making "normal" usage easier and "abnormal" usage harder, and subtly influencing the visual aesthetics of countless future images to match the aesthetic standard imagined by the developers. But there are also significant differences; for example, these algorithms still require real light hitting a sensor, rather than a textual signal from a user. It is also harder to anthropomorphize this sort of an algorithm, with clear deterministic processing steps, versus a stochastic black box text-to-image generative model.
Discussion Questions
- Are smartphone photographs secretly AI images, co-authored by this computational process? Or is there some fundamental boundary between these computational processes and AI image generation?
- The effect of AI image generation on digital art is often compared to the historical effects of photography on portraiture. How does the development of computational photography techniques like this one complicate that narrative?
- Should professional photographers join digital artists in limiting how they share their work online to avoid being included in training data for these systems? Or do the potential benefits for professional photographers outweigh the harms?
- How do Chen and his colleagues at Samsung think about photography? And specifically the concept of a "good" photo? How can we critique the forces that lead smartphone companies to compete over photo quality in the first place?
- Salvaggio (2023) introduces the concept of "seeing like a dataset" — taking photos which fit patterns and go well in a dataset, rather than artistically interesting photos which break them. Are the normative assumptions of image processing "seeing like a dataset?" And how might they play into the aesthetics of text-to-image models?
Bibliography
Chen, George Q. Generation of Bokeh Images Using Adaptive Focus Range and Layered Scattering. US 202111094041 B2, United States Patent and Trademark Office, August 17 2021. USPTO Patent Center https://patentcenter.uspto.gov/applications/16699371
Jiang, Harry H., et al. "AI Art and its Impact on Artists." Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. 2023.
Kopelow, Gerry. How to photograph buildings and interiors. New York, Princeton Architectural Press, 1998, p. 118-9 Accessed via the Internet Archive
Salvaggio, Eryk. "Seeing Like a Dataset: Notes on AI Photography." Interactions 30.3 (2023): 34-37.
Comments
I find everything about this extremely fascinating - and reminiscent of the kinds of things I encountered researching A.I. writing. Namely, the arguments that "all writing is algorithmic writing" and "all writing is unoriginal," positions that became popular in the early- to mid-20th century. Because of course automation technologies start to develop first by automating what was already automatic-ish in human composition: grammatical rules, genre formulae, popular conventions, et al. Human authors don't consider grammatical rules part of their creative contribution. They might play with genre and convention, but they rarely consider the genre or convention the thing that is unique to them.
So I'm convinced: smartphone photographs have been increasingly (and relatively invisibly) automating human composition all along by automating the stuff humans have been relegating as that which is not their unique contribution. As many people have said, photography moved the creative act from the hand to the eye, from brush strokes and materiality to choice of subject matter, framing, etc., and I think that hasn't changed much. Since the ideological separation of mental/creative inspiration from technical skill toward the end of the 18C, that which is constructed as the latter is unmentioned and thus "unprotected" by our cultural outrage toward automation. After all, it is only that "unique contribution" that is considered protected under copyright law.
Your question about some "fundamental boundary" I think is about where we draw that line between the non-technical and the technical, even today. Where do we locate human creative labor in visual art? What are we okay "losing" to the unprotected class of compositional necessities, with grammatical rules, genre formulae, and popular convention? As an amateur painter, I know that I yada yada many of the "skills" that experts would consider fundamental: for instance, the chemistry of linseed oil, turpentine, and oil paints, or the kind of paper and paper finish. I am more than happy to have that prepared for me while I remain ignorant regarding their method. But I don't want to be told what to paint. I don't want someone else to sketch out the lines of the image in my stead.
Thinking to that mid-20th century moment, as computers begin to be used to write poetry and groups like Oulipo experiment with algorithmic writing, I wonder if we're in that moment again, with visual art. Are artists imitating how AI image generation works in their own practice in an effort to locate or question the existence of "creativity"? What is the visual art equivalent of writing a novel with only one vowel or using an N+7 method to replace words? (Perhaps analogous to "seeing like a dataset.") If so, that is quite different than the way photography inspired impressionism.
Writing a second comment because it's unrelated to my first. I want to say two things about taste in relation to your questions about Samsung and smartphone companies.
In Jane Austen’s Northanger Abbey (1803), the protagonist Catherine Morland defines the practice of the picturesque tongue-in-cheekly: “viewing the country with the eyes of persons accustomed to painting and deciding on its capability of being made into pictures with all the eagerness of real taste.” Catherine here is poking fun at the idea that there are gatekeepers who decide on whether a view of a landscape is pretty or not, on whether it is worth being reproduced and shared. (In the scene, she is being mansplained by a potential suitor who is correcting her after she calls a particular view beautiful.) I think in some ways, the technology adding guardrails to digital photography are enforcing a similarly unsolicited amount of taste gatekeeping, inherited from a set of rules once considered arbitrary.
@Zach_Mann I love the ideas explored in your responses. The first point reminds me of Susan Sontag's In Plato's Cave chapter, from On Photography, where she states "to photograph is to appropriate the thing photographed". A major point is that this authority/power of determining what is reality is being transferred to the photograph. Those who have the photograph can proclaim that they have captured the reality, because of the objectivity that we assign photos. It feels resonant with your point of gatekeeping taste or aesthetics, where it even extends to gatekeeping of truth and fact, where only those with a photo can really claim to be presenting what is real.
@Zach_Mann Thank you for the thoughtful responses! You're right that there is a distinction between the technology and the art involved in photography, which resembles the relationship between language, genre, form, etc. and literature. I guess the only thing I would push back on is the idea that these relegated technological aspects are not part of the artist's contribution.
The 19th century art historian Giovanni Morelli believed that the essence of an artist's individual style was actually located in the mundane details of a painting. The hands, ears, or folds of fabric, for example. Artists paid less attention to these parts, so they showed the stylistic differences between otherwise similarly-masterful painters. If the master painters had had a paintbrush with a "draw it normal" button, we would lose those human touches. The Bokeh effect seems similar to that. Part of the craft of the photographer is technically executing an artistic vision, and depending on how they were trained, different photographers will have different muscle memory and technique. If the camera does it for them, everyone using the same camera will arrive at the same normative Bokeh effect. I don't think this is a good or a bad thing, necessarily, but it is less neutral underlying technology and more a part of the resulting art than we might think.
Anyway, my question about a fundamental boundary comes down to the difference between this kind of system and text-to-image generative AI. As far as I can tell, all of these descriptions could apply to text-to-image generative AI, which has a prompt containing the human creativity element and a technological system trained on existing work that generates the image. There, the diffusion model is similar to the Bokeh effect, relegating part of the process from craft to technology. Is the only difference between these systems that artists want to use a paintbrush to paint by hand more than photographers want to adjust their depth of field by hand? Or is there a more fundamental difference? I feel like there really should be, but I struggle to point to it.
Your comparison to algorithmic writing, and "style guides" is apt (I'm also a fan of the early Magic: The Gathering art! The world needs more illustrations like the original Stasis!). When an artistic process like the Bokeh effect is automated, it imposes a normative style which makes the resulting art more consistent, but also more bland. In my previous research, I've written about homogenization of web design, mostly driven by the increasing technological complexity and increasing business importance of consistent web design. AI art is ideal from this business perspective, since you can fine-tune and prompt-engineer models to fit a specific style guide and the model will consistently generate things within that style (and of course you don't pay them). While I hope it doesn't happen, I can totally see Magic cards using AI art in the future for exactly these reasons.
@samgoree thank you for this fascinating critique.
Your move move to interpret the patent documentation of platforms / networks / algorithms in response to closed-source is very creative. I've seen patent critiques in media studies / media archaeology, and that there are a few examples of discussing patents in code studies, but patent-cultural-critique has never been articulated as a body of work to my recollection (although perhaps there is related work in critical legal studies?). A possibly related example in critical code studies specifically the way that Jessica Pressman reads patents in Reading Project -- although in that case she reads patents as an explicit alternative lens in contrast to reading (available) code, not as proxy documentation of algorithms because the code is unavailable.
Regarding your argument:
...I feel that your point here would be made even more compelling with some worked example. I find myself wondering: what might be a concrete instance, whether documented or hypothetical, of a non-normative object being subject to some specific normative bokeh processing based on the recognition enacted through this training dataset? What might be the result of applying the effect? In related areas -- facial recognition algorithms, for example -- the public imagination has often been captured by a concrete illustration that communicates the stakes, such as for example a laptop facial-recognition feature recognizing a white face but not acknowledging a black face.