Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
In this Discussion
The First AIs: IPL-V and Simon&Newell's 1950s (!!) Cognitive Models

For almost exactly a year now, since Team ELIZA got the original ELIZA working, and the book became the team's primary focus, I've been working on reanimating the very first AIs, specifically those written in IPL-V (Information Processing Language Five*) in the 1950s at RAND and Carnegie Tech (now CMU). Mark (Marino) suggested that I open a discussion about some of these earliest IPL-V AIs in this CCS session, and I'm looking for either encouragement or discouragement.
The problem is that, although IPL-V is an incredibly important language, being the language in which Simon and Newell implemented the world's first AIs**, it's also a very difficult language, being essentially the assembly language for a Lisp machine (although Lisp itself wasn't invented until a decade later than the earliest IPL work!) I've made a little video introduction to IPL-V:
If you aren't bored by it, or scared by (or scarred by) all this, let me know, either herebelow, or in DM, and I'll consider making the promised next video introducing LT (The Logic Theory machine, aka. The Logic Theorist) and maybe GPS (The General Problem Solver).
Cheers,
'Jeff
ps. Here's a video that I made about 6 months ago that summarizes my progress at that time on reanimating LT:
Since then my efforts have regressed! :-) Why that has happened is a long, perhaps semi-interesting story.)
(* The fifth IPL is the only one that was fully implemented and commonly available. Most of the previous ones were internal to RAND/CIT. There were plans for an IPL-VI, but it was rolled by Lisp, which implements all the same concepts in a much more elegant language.)
(** What Simon and Newell were working on at RAND in IPL-V wasn't primarily AI, but rather cognitive models; their goal was to build computer programs that thought in the same way that humans thought. To the extent that they succeeded at this, they would have incidentally built an AI by definition, but Simon and Newell preferred terms like "complex information processing" or "cognitive simulation" over "artificial intelligence," which was coined by McCarthy for the 1956 Dartmouth conference. This reflected a genuine philosophical difference: McCarthy pursued intelligence by any effective means, while Simon and Newell insisted their programs should mirror actual human cognitive processes.)
Comments
Hi, so under the assumption that anyone is willing to actually read IPL-V code, the primary sources are a 1960 paper introducing IPL-V, the Logic Theorist paper, and (for more detail) the IPL-V manual. Here they are, and then I'll provide some commentary:
http://bitsavers.informatik.uni-stuttgart.de/pdf/rand/ipl/P-1929_An_Introduction_To_Information_Processing_Language_V_Mar60.pdf
https://www.rand.org/content/dam/rand/pubs/research_memoranda/2009/RM3731.pdf
https://bitsavers.org/pdf/rand/ipl/Information_Processing_Language-V_Second_Edition_1964.pdf
So, start by watching my videos above. Then skim the 1960 show IPL-V intro and esp. p2 where simple lists are described, and then p22 where there is a complete IPL-V routine. (In order to understand the routine on p22 you'll need to back up to the couple of previous pages. A lot of this is described in my IPL-V video, so it will really be helpful to watch that first.)
Then we get to the Logic Theory Machine (usually called the Logic Theorist, or LT). That's the other video. How LT works is described pretty well in the wikipedia page on it:https://en.wikipedia.org/wiki/Logic_Theorist
What we want to look at is the actual code. That's pp. 123-184 of the Stefferud paper, which you should skim, just for shock value. :-) And you can pick any part of this that you feel like, but I recommend going to p12, which has a flowchart of M1, the executive routine, and then you can see the actual routine on p130. It's only about 26 lines long! (Search for "M001" to find the code easily).
And...well...we'll see where we go from there!
Cheers,
'Jeff
This is fascinating -- and thank you for generously sharing such an in-depth guided tour of this project! Thinking about 1950s cognitive models in IPL-V seems more important today and is perfect for thinking about AI (both contemporary and historical) in Critical Code Studies.
I understand that you are presenting a historical sequence and stack of materials, but want to make sure I'm correctly oriented to everything as I come fully up to speed. In particular, as a "code critique," we are centering all of this documentation and context around routine M1 of the Logic Theory Machine, am I right?
The full code is the Logic Theory Machine, as it appears on pp123-184 of:
The recommended starting point or entry point code snippet is the executive routine M1 on p130 -- which is also flowcharted on p12 of the memorandum.
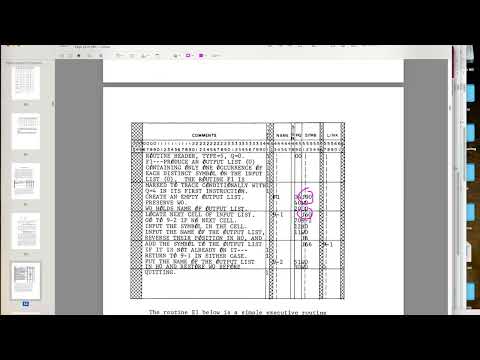
I really struggled with reading the code for M1 on page 130, in large part because was visually chaotic when I wasn't familiar with the format and don't know where the columns begin-end or what columns were named (the code pages lacks column headers or labels). On top of this, it is in the nature of the encoding of Name, Po, Symb, and Link to all appear intermittently, while Po and Symb are formatted to run together. All this creates an illusion that the data is haphazard or misaligned when it is in fact tightly regimented by character position. Further, if you aren't familiar with the name and symbol system, the capital
Oand numeral0are extremely close unless carefully inspected, making it inclear whether1W0=PROB M001R020is 1WO, PR0B, MOO1R020 et cetera. In fact, the embedded OCR in the (password-locked) RAND and DTIC official copies is full of OCR transcription errors throughout, especially on 0s and Os.What do to? As an exercise to work through my own understanding I took the "IPL-V Coding Sheet" on page 187, which shows 80-column data where each band of characters corresponds to Comments (6-40), Type (41), Name (43-47), Sign (48), PO (49-50), Symb (51-55), Link (57-61), Comments (63-72), and ID (73-80). Columns 42, 56, and 62 are blank; columns 0-5 appear to be blank, but 0-4 aren't shown in the reproduction. While the original coding sheet is not a pure typescript, I adapted it to an 80-column fixed-width text format and added as a header to a text file transcript of the PDF page 130 code. Here is the result:
Here is the same data with "|" interjected to make it more legible. This also formats it as a Markdown table:
...and here is that version is rendered live in Markdown:
@jeremydouglass Amazing work; Thank you for that! Yes, card column coding is certainly something that we "moderns" aren't used to reading, and esp. assembly language!
Until you did your work, it hadn't occurred to me that folks might prefer to read a transcription of the code in the paper. We have done that here:
https://docs.google.com/spreadsheets/d/1ibvbyoIT20R4gDqo2iSkk5mJBWsRrtQ6sr8Fj1nz910
M1 starts at about line 37. (Note that the two automatically-computed columns off the right of the code explain what the PQ and symbol mean!)
We did this in part for our reading convenience, but also because we needed to feed the code into the emulator, and, as you point out, OCR'ing it doesn't work. (Rupert Lane, who did the ELIZA reanimation in the 7094->CTSS emulator has a somewhat complex procedure that gets the correct code out of old documents like these, he called "gridlock":
https://github.com/rupertl/gridlock
This should probably be widely advertised, at least in this community!
To your original question about focusing on M1, that's just what I felt was a reasonably important yet at the same time reasonably small and reasonably understandable piece of LT. I'm not fixated on it, and other's might be more interested in reading other parts of the code base. (For which, of course, I recomment using our spreadsheet eventually, but struggling with the same reading problems that led both you and we to make transcriptions has some value, I think, in getting one's head inside what it was like to work with LT in the original.)
Cheers,
'Jeff
I've been deep inside M62 for several days:
Which matches logic expressions that are being proved to expressions that could be used to prove them. This is one of the core and most complex routines in LT. It is particular complex because M62 is RECURSIVE (!!)_ You can see on cards R220 and R370 the function CALLS ITSELF! Unlike Lisp, where recursion was built in underneath the language, IPL programs must manage the recursion stack themselves, pushing things on and popping them off correctly. Having to manage the stack oneself is a good bit of what makes IPL such a painful language to code in. However, one get's used to the tropes, as one does with any language.
The problem I'm having actually seems to be a bug in LT itself, but having worked with the program for a year, now, I'm loathe to jump to the conclusion that LT is wrong -- usually, to date, bugs end up being tracked to a bug in my IPL emulator, or a transcription error, but this appears to be an actual bug in the LT code.
The culprit is actually the very last (or near very last) return: R660. Note that the PQ|Symbol here is: 31H0. What this means is: Pop the stack of the cell whose symbol name is contained in H0. Recall that H0 is the master communication cell -- it's sort of the working memory for the whole system. (There's actually nothing special about H0 as regards the IPL machine -- it's just that H0 is conventionally used in this way.) Very often H0 is pushed and popped, but an indirect cell pop off of H0 is NOT very common. Moreover, I think it's wrong! At the time this executes, H0 contains the name of the expression we've been working on, in this case, "*12" (which, if you care, is:
where "V" mean "OR" and "I" (which unfortunately looks like a vbar) is implication.
The internal representation of that theorem is this:
I've added some notes, preceeded by "<<<<<". You can sort of read off the expression in this uber complex internal representation at comments B through F.
Comment A (<<<<< AAAAA) is actually the problem here. This cell:
has a PQ=14 and a zero symbol. This is a marker used by IPL programmers to mark the list, in this case, to indicate that the list has been processed. The comment at R630 says: "UNMARK IF MARKED", and most of the subsequent code seems to try to do this, by calling J133 (R640), which is test for this exact sort of mark, and then branching (R650). BUT THEN COMES THE PROBLEM! The way it tried to remove the mark seems to be to execute the errant "31H0" command (R660), which, since H0's symbol is *12, tries to pop *12's stack -- note that this is trying to pop the CELL *12's stack, NOT THE LIST *12. It's the LIST, NOT THE CELL, that has the "processed" marker on it that J133 just checked for. And, indeed, the CELL *12 has no stack at all, so when this 31H0 command is called -- that is, when it tried to pop the non-existant *12 cell's stack, this is the result:
Yeah, there i no stack in *12 to pop!
I think what it means to be doing is to call J68, on *12, which is a J function that deletes a cell in a list and closes the list up. That would actually seem to do the right thing, and remove the 14/"0" from *12.
That is, I will replace:
with:
I'm sure you're all sitting on the edge of your seats to see whether this works!
Jeff -- thanks so much for this update.
Regarding the manual recursion in IPL, this seems relevant to the conversation in Gregor's thread code critique of the example from Structure and Interpretation of Computer Programs (SICP), Ch. 1.1 about the role of recursion in that textbook, and, as you point out there, how
My further reponse below is mainly to your previous post. Yes, your spreadsheet is extremely useful -- including the floating annotation of the flowchart near the relevant line on worksheet tab 2! Thank you so much. It is remarkable the labor that can go into thoughtfully transcribing a PDF into something that is once again usefully structured (or thoughtfully semi-automating such transcription). From worksheet to typescript to PDF was a long way for the information to fall.
I think that sometimes the aids that we create for ourselves in decompiling, porting, or reimplementing code are often just the things to help new readers of that code, because they represent a concerted effort to aid understanding.
I am not sorry that I went through that full exercise without knowing that you had already encoded it in a spreadsheet -- sometimes you really do learn a lot on the journey. That said, I'm very glad to learn about Rupert Lane's gridlock and enjoyed reading up on the OCR+LLM grid alignment approach. Having created the text file for one page manually so that I understood the process, the next logical step seemed to be to create a parser for the rest of the pages... but that way lies madness when you don't even have an end emulator in mind, so I'm relieved to know that the work is already being done.
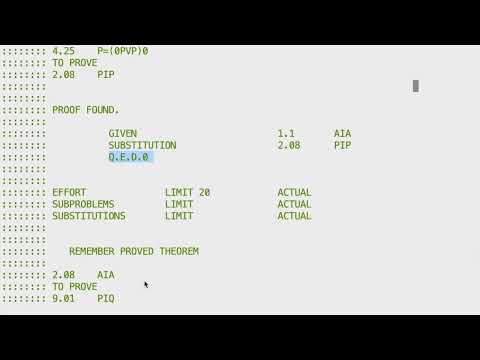
@jeremydouglass We do lots of work in the normal work-a-day software engineering to to make the invisible visible. There are lots of traces in the IPL-V book, and literally half of my IPL-V emulator is debugging code. Here's a block of what it looks like when it's running with the hood open for just 2 cycles (the whole process takes many thousands of cycles, and I'm only tracing 5 cells here; in theory I could trace every relevant cell, but of course that would be WAY bigger -- I already have debugging tools to read my debugging tool outputs!):
@jeremydouglass On the topic of recursion; It really is just stack and memory management (recursion being only one thing that requires stack management -- and stacks being only one of many things that require memory management). A few points. First, Fortran (the only other leading language at the time) cannot (or at least at that time could not) do recursion, because they had static memory management. Also, as Lisp starting eating IPL's lunch (and breakfast and dinner!) the IPL folks actually tried to jump no the s-expression bandwagon, creating the abortive "Linear IPL":


BTW ( @jeremydouglass ) McCarty is also credited with inventing garbage collection, which was another genius invention because it relieved the programmer from doing their own memory management, which on had to do to some extent in IPL (although the language managed the symbol stack memory, which was the most important memory being used for function call stack and thus recursion, and most other memory management was hidden inside J functions, so there wasn't really any need to do a lot of memory management. (I will nod to those who hate GC because it creates unpredictable lags when it kicks in, and at the time, and for highly speed sensitive applications this is partly the case, but these days there's so much memory around that you could just run all day and then kick of a GC "at night" for most applications, and never know it was there.) Anyway, between elegance of representation, elegance of implementation, complete invisibility of memory and stack management, Lisp won ... and once Macros were discovered, it was pretty much over for any other programming language. All the rest are still learning to be more like Lisp.
Sorry that I've had too many start-of-term duties to engage with this week's topic, but this thread triggered a fit of nostalgia, since I was first taught programming on punchcards, then spent years in assembly code before my Master's dissertation in LISP. Since then, I've seen many projects on visualisation and annotation of low-level machines. If anyone would like to build on this great work by making an executable visual annotation, I can certainly see some approaches that might be taken, for a diagrammatic mode of critical reading.
This week (and the last) I've re-approached my IPL-V emulator in honor of this CCS event. I'd dropped it a couple of time before (August of 2025 and October of 2025) partly because I'd got most of the basic machinery to work, and most of the basic test program to work. But the Logic Theorist, which was my Holy Grail (Blue, BTW, in case you're wondering!) remained stubbornly broken. A big step came a couple of months ago when Rupert Lane created GridLock https://github.com/rupertl/gridlock), which correctly OCRs code out of PDFs. This found some recalcitrant typos in our transcription of LT, and I tried again, and got further, but still fell short. Then, this week I decided to pick it up again, and with some distance, just over the past couple of days, made a massive critical discovery which revolutionized my whole understanding of IPL-V and is going to require a rewrite of the two core functions of my emulator (as well as a rewrite of many of the secondary functionalities that rest on that core!)
The problem has to do with stacks. As I've mentioned elsewhere (indeed, everywhere!), IPL is basically the assmbly language for an imaginary stack machine which would essentially be the machine that Lisp could run on (had Lisp been invented a decade before is was!) Indeed, IPL-V is basically Lisp with terrible syntax. And, indeed encore, the raison d'etre of Lisp: Lists [which actually isn't the raison d'etre, most like the raison d'nom :-)] is also the core functionality of IPL -- just as everything in Lisp is a list, everything in IPL is a list!
Now, let's look at that word: "everything". My emulator, alas, did not take to heart this core observation -- the very first line in the very first paragraph of the IPL-V manual by Newell et al.:
Later, however, the manual calls out storage cells:
And here is where I went off the rails. I assume that this means that storage cells were special; that they were a special part of the machine, so my my emulator had (has -- although I'm about to rip this out!) special machinery for storage cells. In addition to a symbol table for cells, there was (is -- "") a special table called the system stack:
And mostly everything worked fine....although LT didn't quite work ... and I had no idea why...until CCS brought me back to this, and I wrote up the long post of a few days ago:
Note the ominous warning to myself:
Well guess what....the last quote above was right, and the one just above was wrong: LT is right, and my emulator is wrong!
The instructional instruction is the one from the previous post, which I reproduce herebelow:
I had hypothesized that this was trying to use the (simulated) hardware of the IPL machine to pop a non-system stack, that is, using PQ=31 to pop the list *12. This shouldn't be doable the way I had understood (and built) the IPL machine where the system stacks were the things manipulated by the machine (PQ=31), and data lists (stacks in the simplest case of a linear list that you push/pop to/from) were handled by J functions, specifically J68.
BUT I WAS WRONG!
In fact, the way that storage cells SHOULD HAVE been implemented was exactly to just push/pop to/from simple linear lists! Then applying PQ=3x to EITHER a system (storage) cell, OR a data stack (like *12) would work perfectly well!
So over the next few days I'm going tear out all my special machinery for storage cells unify the storage cell machinery with the list processing machinery.
Newell was a fucking genius!